pacman::p_load(
dplyr
)6 Les structures de données
Les structures de données de base sous R sont décrites dans la figure Figure 6.1.
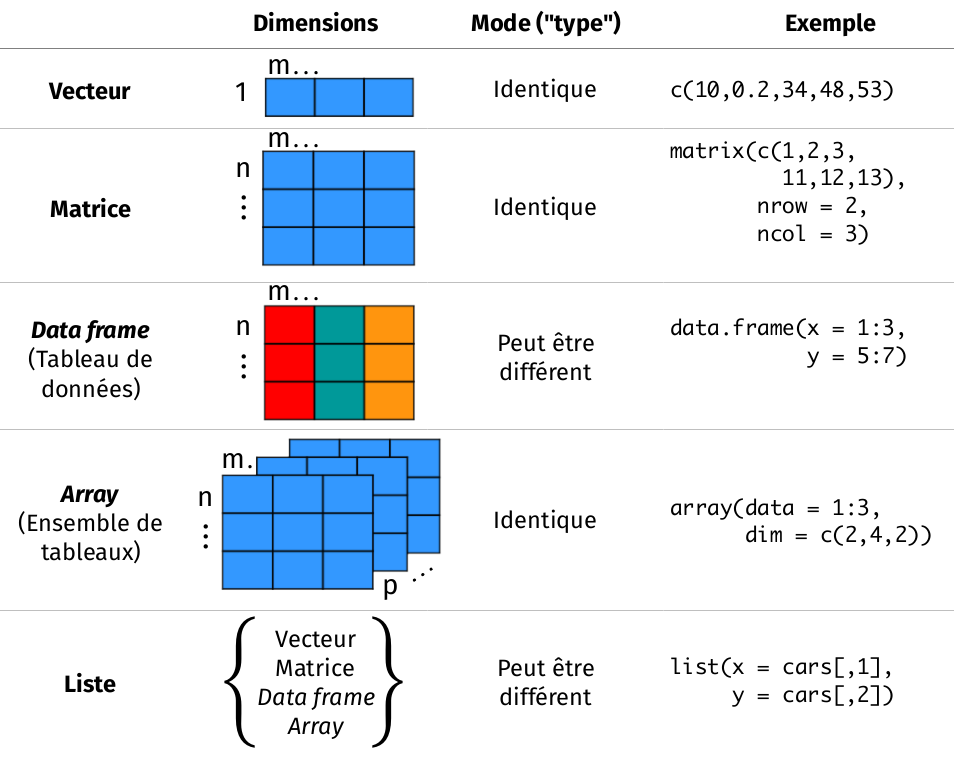
Quand on fait de l’analyse de données sous R, on est surtout confronté aux :
- Variables (structure finie)
- Vecteurs (structure indexée)
- Data frame (structure indexée)
- Matrice (structure indexée) et liste (structure récursive)
Les arrays sont beaucoup moins courants.
6.1 Les variables
En R, et dans les langages de programmation en générale, on stock des informations dans des objets sur lesquels on effectue des opérations. En R, l’objet de base est la variable1. Cette dernière peut être de différentes classes2. Les classes associées aux variables sont : numeric, character et logical.
1 Dans les faits, il s’agit d’un abus de langage. En R, tout est objet, donc une variable n’existe pas vraiment techniquement parlant. On utilise ce mot pour désigner les objets ne contenant qu’une seule valeur.
2 Si vous avez déjà fait de la programmation Orientée Objet (OO), vous devez trouver cela étrange. En R, une classe n’est pas un objet au sens classique où on l’entend en OO mais une étiquette attachée à un un objet.
Une variable de classe numeric correspond à nombre ou un chiffre :
# Définition de variables numeric
n1 <- 1
n2 <- 0.6
n3 <- -5.097
n4 <- 1e6 # Écriture scientifiqueOn assigne une valeur en utilisant <- ou = (on utilisera le <- de préférence car il est idiomatique). Les lignes commençant par # sont des commentaires. Ils sont extrêmements importants car ils vous permettent d’écrire librement du texte dans un script sans qu’il soit interprété comme du code. Vous pouvez ainsi documenter votre code pour faciliter sa lecture par ceux qui le liront.
Pour afficher le contenue d’un objet, on l’écrit dans la console ou on peut utiliser la fonction print() (imprimer) :
n1[1] 1print(n1)[1] 1Pour vérifier la classe d’un objet, on utilise la fonction class() :
class(n1)[1] "numeric"Les variables de classe character enregistre une chaîne de caractères (comme un mot ou un code). Pour la définir, on encadre la valeur par des guillemets simples '' ou doubles "" (utilisez plutôt les guillemets doubles).
# Définition de variables character
c1 <- "a"
c2 <- "arbre"
c3 <- "Une chaîne de caractères plus longue"
c4 <- "LKJHNA2000"
c5 <- "1"Vous voyez qu’un chiffre peut être défini comme un caractère s’il est encadré de guillemets.
Enfin, la classe logical correspond à des booléens : TRUE et FALSE.
b1 <- TRUE
b2 <- FALSE
TipBien nommer ses objets
Comme pour l’écriture des noms de ses fichiers, il convient d’adopter une convention d’écriture que vous utiliserez dans tous vos scripts.
En R, il n’y a pas concenssus sur la convention à utiliser. Cependant, la majorité des personnes utilisent la snake case correspondant à : “tout en miniscule et espace en underscore”. C’est la convention que je vous conseil d’utiliser :
Bien
ma_variabledata_1data_merged
Naze
MaVariableData.1dataMerged
Personnelement, j’enfreint cette convention pour les constantes que j’écrit en majuscule comme en python.
6.2 Les vecteurs
Un vecteur est un ensemble de variables de même classe. On le défini manuellement via la fonction c() (combine). Leur classe est similaire aux classes des variables.
# Vecteur de type numeric
vector_num <- c(1, 2, 4, 5, 6)
vector_num[1] 1 2 4 5 6class(vector_num)[1] "numeric"# Vecteur de type character
vector_str <- c("pluie", "orage", "beau-temps", "pluie", "pluie")
vector_str[1] "pluie" "orage" "beau-temps" "pluie" "pluie" class(vector_str)[1] "character"En R, on a un type particulier de vecteur : les facteurs (factor). Il s’agit de vecteur de chaîne de caractère dont les modalités labelisées. Par défaut, les labels correspondent au nom des modalités elles-mêmes.
vector_str <- c("peu", "moyen", "beaucoup", "peu", "peu")
(factor_vector <- factor(vector_str))[1] peu moyen beaucoup peu peu
Levels: beaucoup moyen peuUn des intérêts des facteurs est que l’on peut leur donner des labels différents :
(factor_vector_labelled <- factor(
vector_str,
levels = c("peu", "moyen", "beaucoup"),
labels = c("Pluiviosité faible", "Pluviosité moyenne", "Pluviosité forte")
))[1] Pluiviosité faible Pluviosité moyenne Pluviosité forte Pluiviosité faible
[5] Pluiviosité faible
Levels: Pluiviosité faible Pluviosité moyenne Pluviosité forteOn peut traiter les facteurs de la même façon que les vecteurs de chaîne de caractères.
6.2.1 Conversion de vecteurs
On peut convertir des vecteurs de la même façon que l’on convertie des variables avec les fonctions as.<class> (par-ex. as.numeric()).
# Conversion d'un vecteur numérique vecteur de chaîne de caractères
(vector_num_str <- as.character(vector_num))[1] "1" "2" "4" "5" "6"class(vector_num_str)[1] "character"(factor_vector <- as.factor(vector_num_str))[1] 1 2 4 5 6
Levels: 1 2 4 5 6class(factor_vector)[1] "factor"6.3 Les Data frame et dérivées
Un Data Frame (DF) est un tableau de données où chaque colonne correspond à un vecteur. Cela correspond à ce que vous traitez d’ordinaire sous excel.
On crée un Data frame avec la fonction data.frame :
(df <- data.frame(
taille = c(185, 166, 180, 164, 173),
prenom = c("Franz", "Richard", "Johan Sebastian", "Ella", "Maria"),
nom = c("Litz", "Wagner", "Bach", "Fitzgerald", "Callas")
)) taille prenom nom
1 185 Franz Litz
2 166 Richard Wagner
3 180 Johan Sebastian Bach
4 164 Ella Fitzgerald
5 173 Maria Callas6.3.1 Accès aux colonnes et aux lignes
Pour accéder à un vecteur (une colonne) dans un DF, plusieurs possibilités :
df$taille # Avec le $
df[["taille"]] # avec [[]]
df[, "taille"] # avec la position
df[, 1] # avec l'index de la colonneOn utilise l’une ou l’autre des méthodes en fonction de la procédure que l’on est entrain d’employer. La méthode $ demeure la plus courante.
Pour accéder aux lignes, on utilise l’index de la ligne. Si le DF a des noms de lignes, on peut également utiliser ces noms.
# Passer une colonne en nom de ligne
(df <- tibble::column_to_rownames(df, "nom")) taille prenom
Litz 185 Franz
Wagner 166 Richard
Bach 180 Johan Sebastian
Fitzgerald 164 Ella
Callas 173 Maria# Extraire la ligne par nom de ligne
df["Litz", ] taille prenom
Litz 185 Franz6.3.2 Description d’un DF
Vous pouvez obtenir une description rapide de votre DF avec la fonction str(). Sur RStudio vous avez ces infos directement dans le panneau Environnement.
str(df)'data.frame': 5 obs. of 2 variables:
$ taille: num 185 166 180 164 173
$ prenom: chr "Franz" "Richard" "Johan Sebastian" "Ella" ...Dans le tableau ci-dessous, vous trouverez d’autres fonction qui permettent de décrire un DF.
| Fonction | Package | Description |
|---|---|---|
str() |
base | Structure générale, types des colonnes, aperçu des valeurs |
glimpse() |
dplyr | Équivalent de str() avec dplyr |
head() |
base | Premières lignes (aperçu des données, pas structurel) |
tail() |
base | Dernières lignes |
names() |
base | Noms des colonnes |
dim() |
base | Dimensions (lignes, colonnes) |
nrow() |
base | Nombre de lignes |
ncol() |
base | Nombre de colonnes |
6.3.3 Les data frame spatiaux
Quand on travail avec des données spatiales vectorielles, ce qui est le cas dans ce cours, on utilise une variante spatiale du Data frame qui est un objet sf issu du package sf.
# Lecture d'un geopackage
path <- "data/src/iris_29.gpkg"
iris <- sf::read_sf(path)
class(iris)[1] "sf" "tbl_df" "tbl" "data.frame"Il s’agit d’un data.frame auquel une colonne qui enregistre la géométrie a été ajoutée. Cette colonne est souvent nommée geom ou geometry. L’objet sf enregistre également le système de coordonnées. Il est donc possible de réaliser des traitements spatiaux comme on le ferait sous QGIS.
NoteQuid des rasters
Il est tout à fait possible de traiter des rasters sous R, notamment avec le package terra. Comme nous n’en utilisons pas dans ce cours, je ne m’étend pas sur le sujet.
6.3.4 Données massives
Dans le cas de données massives (volumineuse), on pourra se tourner vers le package data.table qui possède sa propre syntaxe. Notez qu’on peut maintenant utilisez la syntaxe dplyr avec data.table en utilisant dtplyr.
library(data.table)
library(dtplyr)
# Créer un objet
ldt <- lazy_dt(mtcars)
ldt |>
group_by(cyl) |>
summarise(mpg = sum(mpg))Source: local data table [3 x 2]
Call: `_DT1`[, .(mpg = sum(mpg)), keyby = .(cyl)]
cyl mpg
<dbl> <dbl>
1 4 293.
2 6 138.
3 8 211.
# Use as.data.table()/as.data.frame()/as_tibble() to access results6.4 Les matrices
Comme un DataFrame, une matrice comporte des lignes et des colonnes. La différence entre ces deux objets réside dans le fait qu’une matrice ne comporte que des valeurs numériques.
Pour des manipulations plus avancées, rendez-vous à la Section 8.2.
6.4.1 Création de matrices
On peut créer une matrice avec la fonction matrix() :
# Création d'une matrice 3x3 remplie par colonnes
m1 <- matrix(1:9, nrow = 3, ncol = 3)
m1 [,1] [,2] [,3]
[1,] 1 4 7
[2,] 2 5 8
[3,] 3 6 9# On peut aussi remplir par lignes
m2 <- matrix(1:9, nrow = 3, byrow = TRUE)
m2 [,1] [,2] [,3]
[1,] 1 2 3
[2,] 4 5 6
[3,] 7 8 96.4.2 Accès aux éléments
On peut accéder aux éléments de la matrice de la même façon que dans un dataframe en utilisant l’indice des lignes et des colonnes.
m1[2, 3] # Élément de la 2e ligne, 3e colonne[1] 8m1[1, ] # 1ère ligne complète[1] 1 4 7m1[, 2] # 2e colonne complète[1] 4 5 6Si les lignes et/ou les colonnes sont nommées, on peut également utiliser les noms pour retrouver les valeurs.
colnames(m1) <- paste0("c", 1:3)
rownames(m1) <- paste0("r", 1:3)
m1["r1", "c3"][1] 76.5 Les listes
Voilà une liste imbriquées (nested list) :
gaziers <- list(
"Taylor Swift" = list("argent" = 30, "niveau_de_poulet"=1),
"Bach" = list("argent" = 5, "niveau_de_poulet"=Inf),
"Charlie Parker" = list("argent" = 1, "niveau_de_poulet"=1e6)
)